Create a BigQuery Writer application
Prerequisites for creating a BigQuery Writer application
Before creating a BigQuery target in a Striim application:
Perform the tasks described in Initial BigQuery setup.
Perform any setup tasks required for the application's sources (for example, for Oracle CDC, the tasks described in Configuring Oracle to use Oracle Reader or Configuring Oracle and Striim to use OJet).
Know the BigQuery project ID for the BigQuery project you created as described in Get the project ID for BigQuery.
Know the path to the service account key JSON file you downloaded as described in Download the service account key.
Choose which of the three supported writing methods to use (Storage Write API, legacy streaming API, or load).
Choose which writing mode to use (Append Only or Merge).
If you will Create a BigQuery Writer application using TQL and will not be using schema evolution (see Handling schema evolution), create the dataset(s) and target tables in BigQuery. This is not necessary if you use schema evolution or will Create a BigQuery Writer application using a wizard with Auto Schema Conversion, as in those cases Striim will create the dataset(s) and tables automatically.
Choose which writing method to use
Storage Write API (streaming)
The Storage Write API enables real-time data streaming and writing to BigQuery. With this API, you can write data to BigQuery tables at very high throughput rates and with very low latency, making it ideal for streaming data applications that require real-time insights. This method provides higher performance at lower cost than the others and applications using it will not halt due to exceeding Google's quotas or limits. For more details about the Storage Write API, see BigQuery > Documentation > Guides > Batch load and stream data with BigQuery Storage Write API.
Using this API, incoming data is buffered locally on the Striim server as one memory buffer per target table. Once the upload condition is met, BigQuery Writer makes multiple AppendRows calls to write the content of each memory buffer into the corresponding target table.
To use this method:
Set Streaming Upload to True.
Optionally, change the Streaming Configuration options discussed in BigQuery Writer properties.
Limitations of the Storage Write API:
Data can be queried immediately after it has been written, but updating or deleting those rows may not be possible for up to 30 minutes. See BigQuery > Documentation > Guides > Batch load and stream data with BigQuery Storage Write API > Data manipulation language (DML) limitations for details of this limitation.
Load (default)
This is a legacy method for writing data to BigQuery. The load method uses the TableDataWriteChannel class from the google-cloud-bigquery API.
Striim buffers data locally as one CSV file for each target table. Once the upload condition is met, BigQuery Writer uses TableDataWriteChannel to upload the content of the file to BigQuery, which writes it to the target table. This method may be a good fit if your uploads are relatively infrequent (for example, once in five minutes). On the other hand, if you have applications using the load method and are spending a lot of time tuning those applications' batch policies or are running up against Google's quotas, the Storage Write API method may work better for you.
To use this method:
Leave Streaming Upload at its default setting of False.
If any field might contain the string NULL, set the Null Marker property as discussed in BigQuery Writer properties.
Legacy streaming API
Prior to the release of the Storage Write API, data could be streamed into BigQuery only by using the legacy streaming API. The Storage Write API provides higher performance at lower cost.
Striim supports the legacy streaming API for backward compatibility. We are not aware of any use case where it is preferable to the Storage Write API. After upgrading from Striim 4.1.0 or earlier, an application using this API will be switched to the Storage Write API, but you may alter the application to switch back to the legacy API.
When using the legacy streaming API, Striim buffers data locally as one memory buffer for each target table. Once the upload condition is met, BigQuery Writer will make multiple InsertAllResponse calls, each with a maximum of 10000 rows or 5MB of data, to stream the content of each memory buffer into its target table. By default, up to ten InsertAllResponse calls can run concurrently. This number can be changed using BigQuery Writer's Streaming Configuration property's MaxParallelRequests sub-property.
To use this method:
Set Streaming Upload to True.
Set the Streaming Configuration subproperty UseLegacyStreamingApi to True.
Optionally, change the other Streaming Configuration options discussed in BigQuery Writer properties.
Limitations of the legacy streaming API:
Data can be queried immediately after it has been written, except that for tables partitioned by ingestion time, the _PARTITIONTIME pseudo-column may be null for up to 90 minutes see (BigQuery > Documentation > Guides > Use the legacy streaming API > Streaming data availability).
Choose which writing mode to use
Append Only (default)
In Append Only mode, inserts, updates, and deletes from a Database Reader, Incremental Batch Reader, or SQL CDC source are all handled as inserts in the target. This allows you to use BigQuery to query past data that no longer exists in the source database(s), for example, for month-over-month or year-over-year reports.
Primary key updates result in two records in the target, one with the previous value and one with the new value. If the Tables setting has a ColumnMap that includes @METADATA(OperationName), the operation name for the first event will be DELETE and for the second INSERT.
To use this mode, set Mode to APPENDONLY.
Merge
In Merge mode, inserts, updates, and deletes from Database Reader, Incremental Batch Reader, and SQL CDC sources are handled as inserts, updates, and deletes in the target. The data in BigQuery thus duplicates the data in the source database(s).
In Merge mode:
Since BigQuery does not have primary keys, you may include the
keycolumnsoption in the Tables property to specify a column in the target table that will contain a unique identifier for each row: for example,Tables:'SCOTT.EMP,mydataset.employee keycolumns(emp_num)'. For more information, see Defining relations between source and target using ColumnMap and KeyColumns.You can specify the source tables using wildcards provided you specify
keycolumnsfor all tables and the target table is specified with its three-part name: for example,Tables:'DEMO.%,mydb.mydataset.% KeyColumns(...)'.If you do not specify
keycolumns, Striim will use thekeycolumnsspecified in the source adapter's Tables property as a unique identifier. If the source has nokeycolumns, Striim will concatenate all column values and use that as a unique identifier.
To use this mode:
Set Mode to
Merge.When BigQuery Writer's input stream is the output of an HP NonStop reader, MySQL Reader, or Oracle Reader source and the source events will include partial records, set Optimized Merge to True.
Create the dataset(s) and target tables in BigQuery; partitioning tables
BigQuery Writer writes only to existing tables. If a source table specified in the Tables property does not exist in the target, the application will halt.
When you create your application using a wizard with Auto Schema Conversion, Striim will create the dataset and tables for you automatically (see Using Auto Schema Conversion). However, those tables will not be partitioned.
When using BigQuery Writer's Merge mode, specifying partition columns when creating the target tables can significantly improve performance by reducing the need for full-table scans. See BigQuery > Documentation > Guides > Introduction to partitioned tables and BigQuery > Documentation > Guides > Creating partitioned tables for more information. You cannot partition an existing table.
When BigQuery Writer's input stream is of type WAEvent and a database source column is mapped to a target table's partition column:
for INSERT events, the partition column value must be in the WAEvent
dataarray.for UPDATE events, the partition column value must be in the WAEvent
beforearray.
When this is not the case, the batch requires a full-table scan.
If your application updates partition column values, specify the source table primary key and partition column names in keycolumns in the Tables property. For example, If id is the primary key in the source table and purchase_date is the partition column in BigQuery, the Tables property value would be <schema name>.<table name>, <dataset name.<table name> KeyColumns(id, purchase_date). For more information, see Defining relations between source and target using ColumnMap and KeyColumns.
Limitations when using partitioned tables:
BigQuery Writer's Standard SQL property must be True.
If source events include partial records and the values for the partition column are not included, BigQuery's Require partition filter option (see BigQuery > Documentation > Guides > Managing partitioned table > Set partition filter requirements) must be disabled on all tables for which there are partial records. If it is not, if and when a full-table scan is required (see BigQuery > Documentation > Guides > Introduction to partitioned tables), the application will halt.
See BigQuery > Documentation > Guides > Introduction to partitioned tables > Limitations and Quotas and limits for additional limitations. (Quotas are subject to change by Google.)
Create a BigQuery Writer application using a wizard
In Striim, select Apps > Create New, enter BigQuery in the search bar, click the kind of application you want to create, and follow the prompts. See Creating apps using wizards for more information.
Create a BigQuery Writer application using TQL
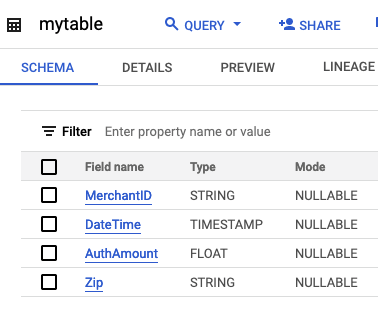
This simple application reads data from a .csv file from the PosApp sample application and writes it to BigQuery. In this case, BigQuery Writer has an input stream of a user-defined type. The sample code assumes that you have created the following table in BigQuery:
CREATE SOURCE PosSource USING FileReader (
wildcard: 'PosDataPreview.csv',
directory: 'Samples/PosApp/appData',
positionByEOF:false )
PARSE USING DSVParser (
header:Yes,
trimquote:false )
OUTPUT TO PosSource_Stream;
CREATE CQ PosSource_Stream_CQ
INSERT INTO PosSource_TransformedStream
SELECT TO_STRING(data[1]) AS MerchantId,
TO_DATE(data[4]) AS DateTime,
TO_DOUBLE(data[7]) AS AuthAmount,
TO_STRING(data[9]) AS Zip
FROM PosSource_Stream;
CREATE TARGET BigQueryTarget USING BigQueryWriter(
ServiceAccountKey:"/<path>/<file name>.json",
projectId:"myprojectid-123456",
Tables: 'mydataset.mytable'
)
INPUT FROM PosSource_TransformedStream;After running this application, open the console, run select * from mydataset.mytable; and you will see the data from the file. Since the default timeout is 90 seconds, it may take that long after the application completes before you see all 1160 records in BigQuery.